YOLO (You Only Look Once) es un algoritmo de detección de objetos que utiliza técnicas de aprendizaje profundo (deep learning). Por lo tanto, es más específicamente una técnica dentro del campo de la inteligencia artificial (AI) que utiliza redes neuronales convolucionales (CNN) para realizar la tarea de detección de objetos en imágenes o videos.
YOLO, fue inventado por Joseph Redmon, Santosh Divvala, Ross Girshick y Ali Farhadi en la Universidad de Washington. El artículo original que describe el método YOLO fue publicado en 2016 por Joseph Redmon y Ali Farhadi. El stack tecnológico inicial de la aplicación YOLO incluye:
- Python: YOLO está implementado principalmente en el lenguaje de programación Python, que es ampliamente utilizado en el campo del aprendizaje profundo y la visión por computadora debido a sus numerosas bibliotecas y marcos de trabajo disponibles.
- CUDA: Es una plataforma de computación paralela desarrollada por NVIDIA que permite aprovechar el poder de las GPU para acelerar operaciones intensivas en cálculos, como los utilizados en las redes neuronales profundas. YOLO hace uso de CUDA para la aceleración de la inferencia en GPU.
- OpenCV: Es una biblioteca de visión por computadora de código abierto que proporciona una serie de funciones y algoritmos útiles para el procesamiento de imágenes y videos. YOLO utiliza OpenCV para manipular imágenes de entrada y visualizar las detecciones de objetos.
- Darknet: Es un marco de aprendizaje profundo de código abierto escrito en C y CUDA. Fue desarrollado por Joseph Redmon específicamente para el proyecto YOLO. Originalmente, YOLO se implementó en Darknet.
- TensorFlow: Es un marco de aprendizaje automático de código abierto desarrollado por Google. Si bien la implementación original de YOLO se basaba principalmente en Darknet, que utiliza su propio marco personalizado, versiones y adaptaciones posteriores de YOLO se han implementado utilizando TensorFlow. TensorFlow proporciona una plataforma flexible y potente para construir y entrenar modelos de aprendizaje profundo, incluidos los modelos de detección de objetos como YOLO.
- PyTorch: Es otro marco de aprendizaje automático de código abierto desarrollado por el laboratorio de investigación de inteligencia artificial de Facebook (FAIR). Al igual que TensorFlow, PyTorch se ha utilizado para implementar modelos YOLO en varios proyectos y documentos de investigación. PyTorch es conocido por su gráfico de cálculo dinámico, lo que facilita definir y modificar arquitecturas de redes neuronales complejas.
Estos componentes formaron el núcleo inicial de la implementación de YOLO y permitieron su desarrollo y uso efectivo en una variedad de aplicaciones de detección de objetos. A lo largo del tiempo, han surgido varias implementaciones y versiones de YOLO, algunas de las cuales pueden haber utilizado tecnologías y bibliotecas diferentes, pero esta fue la configuración inicial y más comúnmente asociada con YOLO en sus primeras etapas.
Para este artículo, implementamos Yolov8 usando ultralíticos:
¿Qué es YOLOv8?
YOLOv8 es un nuevo modelo de visión por computadora de última generación creado por Ultralytics, los creadores de YOLOv5. El modelo YOLOv8 contiene soporte listo para usar para tareas de detección, clasificación y segmentación de objetos, accesible a través de un paquete Python y una interfaz de línea de comandos.
Preparando Ambiente y configuración
Las especificaciones mínimas necesarias para ejecutar YOLOv8 de Ultralytics pueden diferir según una variedad de variables, incluido el tamaño del modelo, el tamaño de la imagen de entrada y la cantidad de objetos a detectar. Sin embargo, la siguiente es una lista amplia de requisitos previos en los que quizás desee considerar:
Normalmente, se crea un entorno virtual para aislar proyectos, ya que pueden tener muchas dependencias específicas necesarias solo para ese proceso. Esta es una práctica recomendada para garantizar el uso de los componentes correctos y evitar que afecten a otros proyectos.
Preparación del entorno
Las especificaciones mínimas necesarias para ejecutar YOLOv8 de Ultralytics pueden diferir según una variedad de variables, incluido el tamaño del modelo, el tamaño de la imagen de entrada y la cantidad de objetos a detectar. Sin embargo, la siguiente es una lista amplia de requisitos previos en los que quizás desee considerar:
Hardware:
- Procesador: Se recomienda un procesador moderno con al menos 4 núcleos.
- RAM: Se recomienda al menos 8 GB de RAM.
- GPU (opcional pero muy recomendable): se recomienda una GPU NVIDIA compatible con CUDA para la aceleración de inferencia por GPU. Las GPU más potentes proporcionarán un rendimiento más rápido.
Software:
- Sistema operativo: YOLOv8 de Ultralytics es compatible con Windows, Linux y macOS; casi compatible con todos ellos.
- Python: Python debe estar instalado; Se recomienda instalar Python en versiones superiores a la 3.7.
Para instalar Python: Download Python | Python.org Este articulo fue creado con la versión 3.12.2 de Python.
Entorno virtual (virtualenv):
Normalmente, se crea un entorno virtual para aislar proyectos, ya que pueden tener muchas dependencias específicas necesarias sólo para ese proceso. Esta es una práctica recomendada para garantizar que utiliza los componentes correctos y evitar que afecten a otros proyectos.
Crear la carpeta del proyecto y entrar en ella.
mkdir myAIapp
cd myAIappCreación de entorno virtual usando python.
Por lo general, el entorno virtual se crea en la carpeta donde está posicionada la consola, en este caso particular al movernos a la carpeta que creamos, myAIapp debe haberla creado allí.
#cambia el nombre si quieres llamar a tu entorno de manera diferente, en este caso es my_env
python3 -m venv my_envPara saber qué se creó, se tuvo que haber creado una carpeta con el nombre del entorno que creaste. Puede usar el comando ls para verlo en Linux o Mac y en Windows usar dir.
.. para activar el entorno.
En Linux o Mac.
Navegue hasta el directorio donde se encuentra su entorno virtual. Por ejemplo, en este caso en la carpeta del proyecto:
source my_env/bin/activateEn Windows.
Lo mismo en la carpeta del proyecto.
.my_env\Scripts\activateNota: Si cambias el nombre del entorno virtual deberás cambiarlo para que no tenga errores.
Note: If you change the name of the virtual environment, you must change it so that it does not have errors.

Como puede ver, ahora estamos dentro del entorno virtual my_env, generalmente cuando este es el caso se muestra entre paréntesis en la consola.
Configuración del entorno
Con todo instalado procederemos a instalar las dependencias necesarias para este proyecto, en este caso solo instalaremos dos en el entorno virtual creado.
Instalación de OpenCV.
pip install opencv-pythonInstalación de OpenCV.
pip install ultralyticsComience a transmitir con la cámara web
Para este punto solo usaremos OpenCv, que se encarga de acceder a la cámara del ordenador.
# Importar la biblioteca OpenCV
import cv2
# Abrir la cámara predeterminada (índice 0), si incluyes otras como una webcam externa puedes cambiarlo a (1)
cap = cv2.VideoCapture(0)
# Establecer el ancho del fotograma en 640 píxeles
cap.set(3, 640)
# Establecer la altura del fotograma en 480 píxeles
cap.set(4, 480)
# Bucle infinito para capturar continuamente fotogramas de la cámara
while True:
# Leer un fotograma de la cámara
ret, img = cap.read()
# Mostrar el fotograma capturado en una ventana llamada "Cam"
cv2.imshow('Cam', img)
# Esperar una pulsación de tecla durante 1 milisegundo
# Si la tecla presionada es 'q', salir del bucle
if cv2.waitKey(1) == ord('q'):
break
# Liberar la cámara
cap.release()
# Cerrar todas las ventanas de OpenCV
cv2.destroyAllWindows()Podemos guardar el archivo como camera.py. y ejecute el siguiente comando.
Asegúrese de estar en la ubicación raíz donde se encuentra el archivo; en este caso, estaría en myAIapp y el archivo en myAIapp/camera.py.
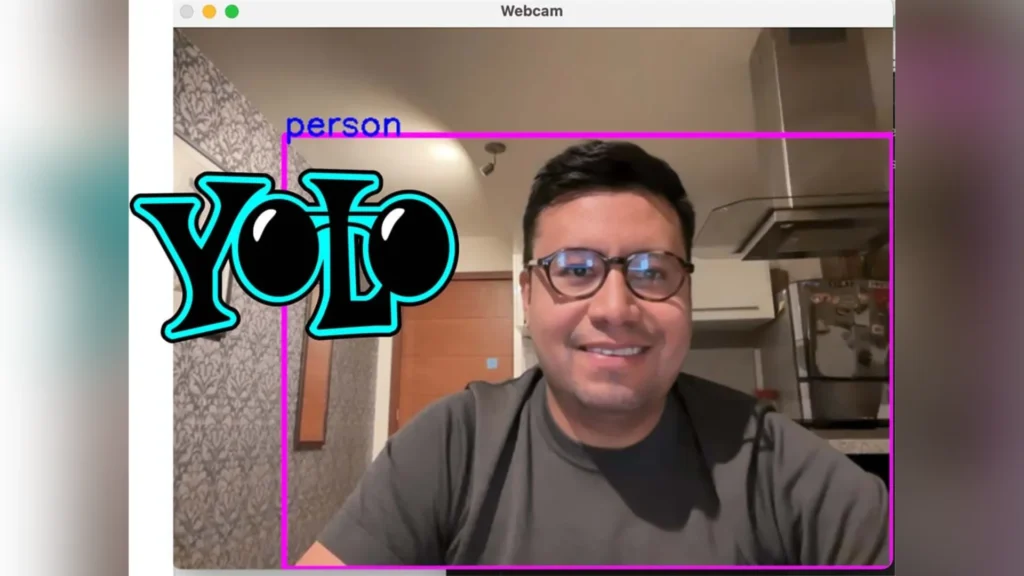
python3 camera.py
Ejecutar la detección de objetos con Yolov8.
Al inicio de este proceso, descargará automáticamente un modelo ya realizado con las categorías que se muestran a continuación. YOLO (“yolo- Weights/yolov8n.ptˮ)
Al descargar el modelo, se creará una carpeta en la raíz del proyecto llamada yolo-Weights, y allí se guardará.
Clases para este modelo:
classNames = ["person", "bicycle", "car", "motorbike", "aeroplane", "bus", "train", "truck", "boat",
"traffic light", "fire hydrant", "stop sign", "parking meter", "bench", "bird", "cat",
"dog", "horse", "sheep", "cow", "elephant", "bear", "zebra", "giraffe", "backpack", "umbrella",
"handbag", "tie", "suitcase", "frisbee", "skis", "snowboard", "sports ball", "kite", "baseball bat",
"baseball glove", "skateboard", "surfboard", "tennis racket", "bottle", "wine glass", "cup",
"fork", "knife", "spoon", "bowl", "banana", "apple", "sandwich", "orange", "broccoli",
"carrot", "hot dog", "pizza", "donut", "cake", "chair", "sofa", "pottedplant", "bed",
"diningtable", "toilet", "tvmonitor", "laptop", "mouse", "remote", "keyboard", "cell phone",
"microwave", "oven", "toaster", "sink", "refrigerator", "book", "clock", "vase", "scissors",
"teddy bear", "hair drier", "toothbrush"
]Código para identificar objetos definidos en la clase usando la cámara web de la computadora:
# Importar librerías
from ultralytics import YOLO # Importar el modelo YOLO de Ultralytics
import cv2 # Importar la biblioteca OpenCV
import math # Importar el módulo math para operaciones matemáticas
# Iniciar la webcam
cap = cv2.VideoCapture(0) # Abrir la cámara predeterminada (índice 0)
cap.set(3, 640) # Establecer el ancho del fotograma en 640 píxeles
cap.set(4, 480) # Establecer la altura del fotograma en 480 píxeles
# Cargar el modelo YOLO
model = YOLO("yolo-Weights/yolov8n.pt") # Cargar el modelo YOLOv8 con pesos pre-entrenados
# Definir las clases de objetos para la detección
classNames = ["persona", "bicicleta", "coche", "motocicleta", "avión", "autobús", "tren", "camión", "bote",
"semáforo", "boca de incendios", "señal de stop", "parquímetro", "banco", "pájaro", "gato",
"perro", "caballo", "oveja", "vaca", "elefante", "oso", "cebra", "jirafa", "mochila", "paraguas",
"bolso", "corbata", "maleta", "frisbee", "esquís", "snowboard", "balón deportivo", "cometa", "bate de béisbol",
"guante de béisbol", "monopatín", "tabla de surf", "raqueta de tenis", "botella", "copa de vino", "taza",
"tenedor", "cuchillo", "cuchara", "cuenco", "plátano", "manzana", "sándwich", "naranja", "brócoli",
"zanahoria", "perrito caliente", "pizza", "donut", "pastel", "silla", "sofá", "planta en maceta", "cama",
"mesa de comedor", "retrete", "monitor de TV", "ordenador portátil", "ratón", "control remoto", "teclado", "teléfono móvil",
"microondas", "horno", "tostadora", "fregadero", "refrigerador", "libro", "reloj", "florero", "tijeras",
"oso de peluche", "secador de pelo", "cepillo de dientes"
]
# Bucle infinito para capturar continuamente fotogramas de la cámara
while True:
# Leer un fotograma de la cámara
success, img = cap.read()
# Realizar la detección de objetos utilizando el modelo YOLO en el fotograma capturado
results = model(img, stream=True)
# Iterar a través de los resultados de la detección de objetos
for r in results:
boxes = r.boxes # Extraer las cajas delimitadoras de los objetos detectados
# Iterar a través de cada caja delimitadora
for box in boxes:
# Extraer coordenadas de la caja delimitadora
x1, y1, x2, y2 = box.xyxy[0]
x1, y1, x2, y2 = int(x1), int(y1), int(x2), int(y2) # Convertir a valores enteros
# Dibujar la caja delimitadora en el fotograma
cv2.rectangle(img, (x1, y1), (x2, y2), (255, 0, 255), 3)
# Calcular e imprimir la puntuación de confianza de la detección
confidence = math.ceil((box.conf[0]*100))/100
print("Confianza --->", confidence)
# Determinar e imprimir el nombre de la clase del objeto detectado
cls = int(box.cls[0])
print("Nombre de la clase -->", classNames[cls])
# Dibujar texto indicando el nombre de la clase en el fotograma
org = [x1, y1]
font = cv2.FONT_HERSHEY_SIMPLEX
fontScale = 1
color = (255, 0, 0)
thickness = 2
cv2.putText(img, classNames[cls], org, font, fontScale, color, thickness)
# Mostrar el fotograma con los objetos detectados en una ventana llamada "Cam"
cv2.imshow('Cam', img)
# Comprobar si se presionó la tecla 'q' para salir del bucle
if cv2.waitKey(1) == ord('q'):
break
# Liberar la cámara
cap.release()
# Cerrar todas las ventanas de OpenCV
cv2.destroyAllWindows()
Podemos guardar el archivo como object-cam.py. y ejecute el siguiente comando.
Asegúrese de estar en la ubicación raíz donde se encuentra el archivo; en este caso, estaría en myAIapp y el archivo en myAIapp/object-cam.py.
python3 object-cam.py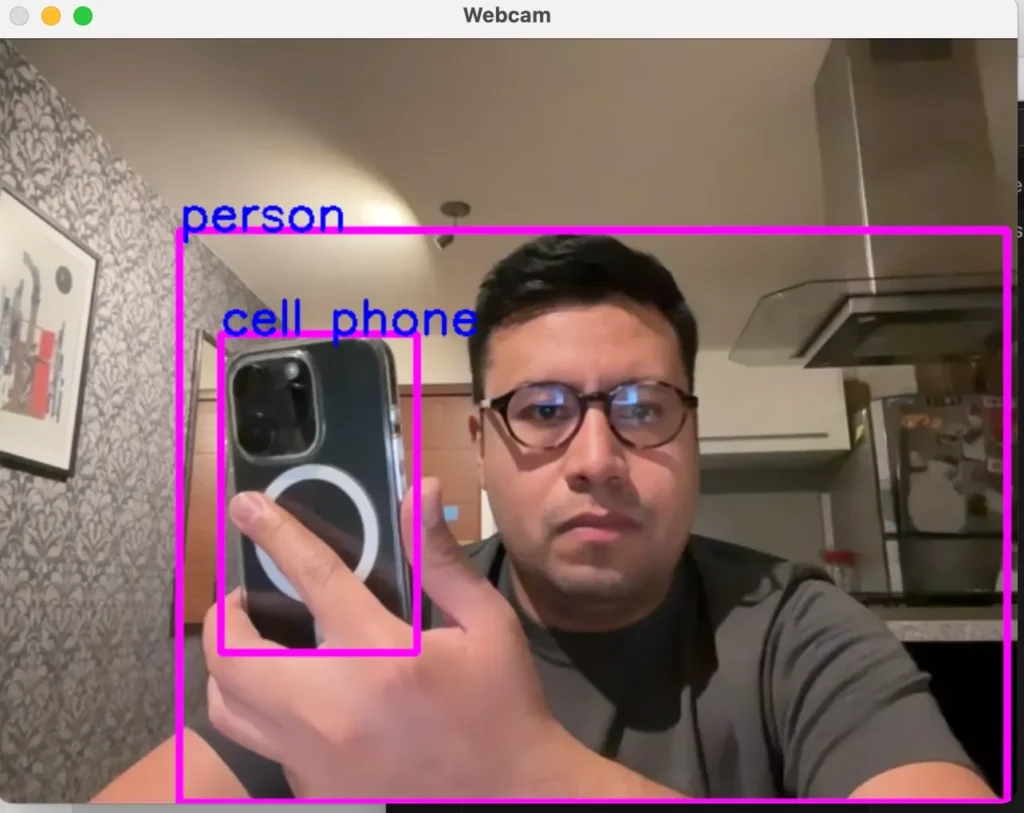
Ahora es funcional, el modelo puede detectar hasta 80 clases y puede usarse para innumerables casos de uso.
Referencia:
YOLOv8: A New State-of-the-Art Computer Vision Model
YOLO: Real-Time Object Detection (pjreddie.com)

